Multitasking Management in the Operating System Kernel
这篇文章翻译自KUKURUKU.
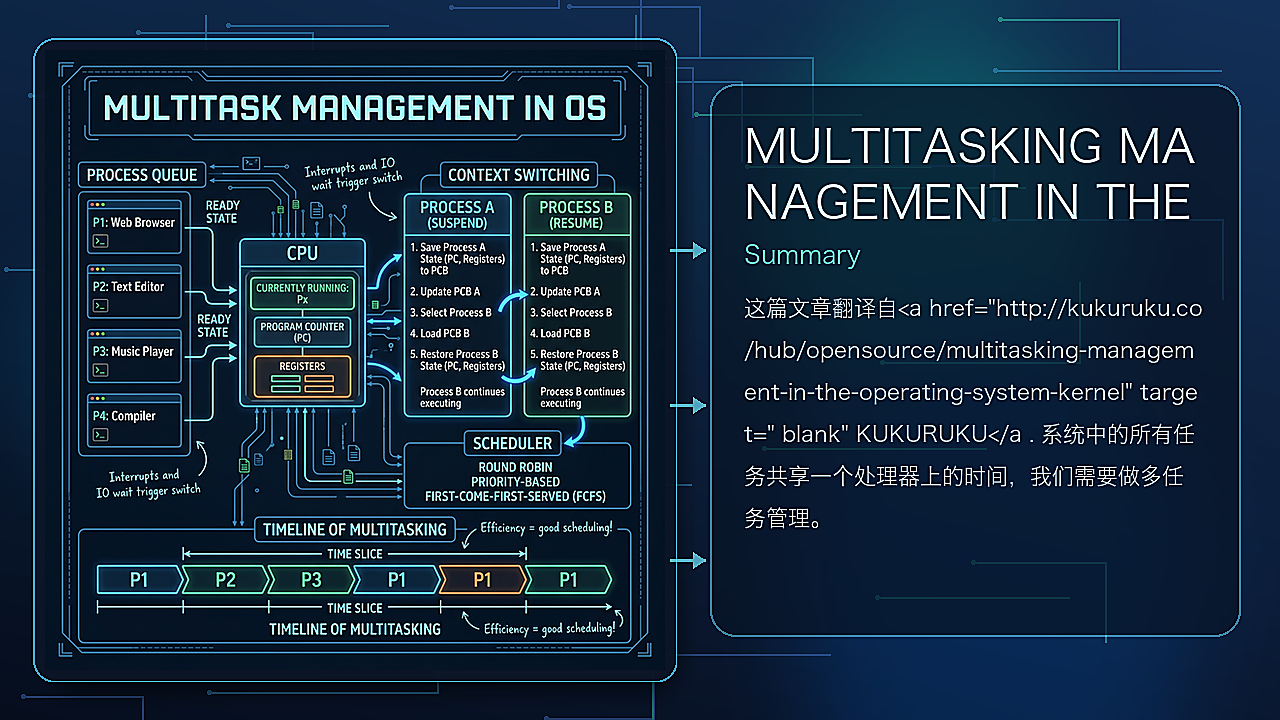
系统中的所有任务共享一个处理器上的时间,我们需要做多任务管理。或者说伪多任务,因为所有任务是共享一个处理器上的时间。首先,我会介绍多任务的类型(协作式/抢占式);然后我会继续介绍抢占式多任务中的调度原则。这篇文章已经针对第一次想从内核级别上理解多任务的读者做了优化。但是文中的实例都可以编译运行,那些已经熟悉理论,但是从未真正“尝试”调度器的读者也会感兴趣。
介绍
首先介绍一下多任务的含义,下面是维基百科的定义:
In computing, multitasking is a method where multiple tasks, also known as processes, are performed during the same period of time. The tasks share common processing resources, such as a CPU and main memory. In the case of a computer with a single CPU, only one task is said to be running at any point in time, meaning that the CPU is actively executing instructions for that task. Multitasking solves the problem by scheduling which task my by the one running at any given time, and when another waiting task gets a turn. The act of reassigning a CPU from one task to another one is called a context switch.
在上述定义中提到了资源共享和调度的概念,本文在后面部分会继续关注,我会基于线程来描述线程。
所以,我们需要再引入一个概念,让我们称之为调度线程(scheduling thread)。它是CPU在程序运行期间按顺序执行的一系列指定集合。
我们提到了多任务,当然,在系统是可以有多个计算线程。当前处理器正在执行指令所属的线程的状态为活跃(active)。因为在单处理器系统中,在某一个时刻只有一个指令可以执行,所以只有一个线程处于活跃状态。处理器选择active线程的过程称为调度,负责线程选择的模块称为调度器。

在系统中有多种调度方法,基本上可以分为两个大类:
- 协作式(Cooperative),调度器不能剥夺正在计算的线程的时间,除非它主动放弃
- 抢占式(Preemtive),当时间片结束,调度器选择下一个active的线程;该线程也可以放弃它所剩余的时间片
首先来分析一下协作调度,因为它较容易实现。
协作调度器
本文所考虑的协作调度器很简单,所列举的例子适合初学者,以为这样他们更容易理解多任务。理解理论概念的读者可以直接跳至“抢占式调度器”部分继续阅读。
基本协作调度器
假设我们有多个任务,运行时间很短,我们可以依次调度它们。我们将利用一些带参数的普通函数来描述任务。调度器会在这些函数组成的数组上完成操作。它会调用任务函数的初始化函数。当每一个任务所有必需的操作都执行后,函数会返回主调度器循环执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include <stdio.h>
#define TASK_COUNT 2
stuct taks
{
void (*func)(void *);
void *data)
};
static struct task tasks[TASK_COUNT];
static void scheduler(void)
{
int i;
for (int i = 0; i < TASK_COUNT; ++i)
{
tasks[i].func(tasks[i].data);
}
}
static void worker(void *data)
{
printf("%s\", (char*)data);
}
static struct task *task_create(void (*func)(void*), void *data)
{
static int i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
int main(void)
{
task_create(&worker, "First");
task_create(&worker, "Second");
scheduler();
return 0;
}
Output Result:
First
Second
CPU使用图如下:

带基本事件处理的协作调度器
当然,上面例子中的调度器太多原始。让我们引入一种激活任务的功能。为了实现此目的,我们需要在结构中增加一个标记。该标记指示任务是否处于激活状态,我们需要增加一些API来管理该激活过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
#include <stdio.h>
#define TASK_COUNT 2
struct task
{
void (*func)(void*);
void *data;
int activated;
};
static struct task tasks[TASK_COUNT];
struct task_data
{
char *str;
struct task *next_task;
};
static struct task *task_create(void (*func)(void*), void *data)
{
static int i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
static int task_activate(struct task *task, void *data)
{
task->data = data;
task->activated = 1;
return 0;
}
static int task_run(struct task *task, void *data)
{
task->activated = 0;
task->func(data);
return 0;
}
static void scheduler(void)
{
int i;
int fl = 1;
while (fl)
{
fl = 0;
for (i = 0; i < TASK_COUNT; ++i)
if (tasks[i].activated)
{
fl = 1;
task_run(&tasks[i], tasks[i].data);
}
}
}
static void worker1(void *data)
{
printf("%s\n", (char*) data);
}
static void worker2(void *data)
{
struct task_data *task_data;
task_data = data;
printf("%s\n", task_data->str);
task_activate(task_data->next_task, "First activated");
}
int main(void)
{
struct task *t1, *t2;
struct task_data task_data;
t1 = task_create(&worker1, "First create");
t2 = task_create(&worker2, "Second create");
task_data.next_task = t1;
task_data.str = "Second activated";
task_activate(t2, &task_data);
scheduler();
return 0;
}
Output Result:
Second activated
First activated
CPU使用图如下:

带消息队列的协作调度器
上面方案的问题很明显。如果某个人想将同一个任务激活两次,除非该任务执行结束,否则它不可能做到,第二次激活的信息被阻塞了。该问题可以通过消息队列的方式部分解决。我们加入一个数组取代标记,它将存储每个线程的消息队列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
#include <stdio.h>
#include <stdlib.h>
#define TASK_COUNT 2
struct message {
void *data;
struct message *next;
};
struct task {
void (*func)(void *);
struct message *first;
};
struct task_data {
char *str;
struct task *next_task;
};
static struct task tasks[TASK_COUNT];
static struct task *task_create(void (*func)(void *), void *data) {
static int i = 0;
tasks[i].func = func;
tasks[i].first = NULL;
return &tasks[i++];
}
static int task_activate(struct task *task, void *data) {
struct message *msg;
msg = malloc(sizeof(struct message));
msg->data = data;
msg->next = task->first;
task->first = msg;
return 0;
}
static int task_run(struct task *task, void *data) {
struct message *msg = data;
task->first = msg->next;
task->func(msg->data);
free(data);
return 0;
}
static void scheduler(void) {
int i;
int fl = 1;
struct message *msg;
while (fl) {
fl = 0;
for (i = 0; i < TASK_COUNT; i++) {
while (tasks[i].first) {
fl = 1;
msg = tasks[i].first;
task_run(&tasks[i], msg);
}
}
}
}
static void worker1(void *data) {
printf("%s\n", (char *) data);
}
static void worker2(void *data) {
struct task_data *task_data;
task_data = data;
printf("%s\n", task_data->str);
task_activate(task_data->next_task, "Message 1 to first");
task_activate(task_data->next_task, "Message 2 to first");
}
int main(void) {
struct task *t1, *t2;
struct task_data task_data;
t1 = task_create(&worker1, "First create");
t2 = task_create(&worker2, "Second create");
task_data.next_task = t1;
task_data.str = "Second activated";
task_activate(t2, &task_data);
scheduler();
return 0;
}
Output Results:
Second activated
Message 2 to first
Message 1 to first
CPU使用情况如下:

带调用顺序存储的协作调度器
上述方案的另外一个问题是任务激活的顺序没有存储。每一个任务安排自己的优先级,通常这并不好。为了解决这个问题,可以通过再创建一个消息队列和一个检测程序来解决这个问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
#include <stdio.h>
#include <stdlib.h>
#define TASK_COUNT 2
struct task {
void (*func)(void *);
void *data;
struct task *next;
};
static struct task *first = NULL, *last = NULL;
static struct task *task_create(void (*func)(void *), void *data) {
struct task *task;
task = malloc(sizeof(struct task));
task->func = func;
task->data = data;
task->next = NULL;
if (last) {
last->next = task;
} else {
first = task;
}
last = task;
return task;
}
static int task_run(struct task *task, void *data) {
task->func(data);
free(task);
return 0;
}
static struct task *task_get_next(void) {
struct task *task = first;
if (!first) {
return task;
}
first = first->next;
if (first == NULL) {
last = NULL;
}
return task;
}
static void scheduler(void) {
struct task *task;
while ((task = task_get_next())) {
task_run(task, task->data);
}
}
static void worker2(void *data) {
printf("%s\n", (char *) data);
}
static void worker1(void *data) {
printf("%s\n", (char *) data);
task_create(worker2, "Second create");
task_create(worker2, "Second create again");
}
int main(void) {
struct task *t1;
t1 = task_create(&worker1, "First create");
scheduler();
return 0;
}
Outpt Result:
First create
Second create
Second create again
CPU使用情况如下:

在继续讲解抢占式调度器之前,我想说明在实际系统中任务切换的代价很低。这个途径需要程序员特别的关注,它需要注意到在性能测试时不要让任务死循环。
#抢占式调度器

首先做如下假设。在同一个执行的程序中有个计算线程。在任意有个指令执行期间,调度器可以中断一个激活的线程,激活另外一个线程。为了管理这种任务,向协作调度器那样保存任务的执行函数和参数是不够的。你必须至少知道当前执行指令的地址和每个任务局部变量的集合的地址。所以,你必须保存每个任务变量的备份。因为线程中的局部变量是被隔开的,必须分配一些空间来保存线程的栈;那个地方也应该存储栈的当前位置。
这些数据:指令指针和栈指针会存储在处理器寄存器中。除了他们,为了正常工作还要保存其它信息,这些信息也存储在寄存器中,包括状态标记,不同通用目的寄存器(存储临时变量)等。上述所有的信息称为CPU上下文(CPU context)。
CPU context

处理器上下文(Processor context/CPU context)是一种存储处理器寄存器内部状态的数据结构。该上下文必须把处理器转至一个计算线程执行的正确状态。处理器处理的线程由一个切换至另外一个称为上下文切换(context switch)。
我们项目中x86架构中的上下文数据结构描述如下:
1
2
3
4
5
6
7
8
9
struct context {
/* 0x00 */uint32_t eip; /**< instruction pointer */
/* 0x04 */uint32_t ebx; /**< base register */
/* 0x08 */uint32_t edi; /**< Destination index register */
/* 0x0c */uint32_t esi; /**< Source index register */
/* 0x10 */uint32_t ebp; /**< Stack pointer register */
/* 0x14 */uint32_t esp; /**< Stack Base pointer register */
/* 0x18 */uint32_t eflags; /**< EFLAGS register hold the state of the processor */
};
CPU上下文和上下文切换的概念是理解抢占式调度器的基础。
Context switch
上下文切换是指线程执行的切换。调度器保存当前的上下文,然后将处理器的寄存器恢复至另外一个上下文。
在之前我已经提到:调度器可以中断任何一个激活的线程,这实际上在某些方面简化模式。现实中,不仅调度器会中断线程,CPU在响应外部硬件中断事件时也会中断线程。,执行中断处理后会将控制权返回调度器。例如,假设外部事件是系统计时器,它负责记录激活线程的所使用的时间片。我们假设系统只有系统计时器一个中断源,那么处理的时间图和下图相近:

在x86架构上的上下文切换过程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
.global context_switch
context_switch:
movl 0x04(%esp), %ecx /* Point ecx to previous registers */
movl (%esp), %eax /* Get return address */
movl %eax, CTX_X86_EIP(%ecx) /* Save it as eip */
movl %ebx, CTX_X86_EBX(%ecx) /* Save ebx */
movl %edi, CTX_X86_EDI(%ecx) /* Save edi */
movl %esi, CTX_X86_ESI(%ecx) /* Save esi */
movl %ebp, CTX_X86_EBP(%ecx) /* Save ebp */
add $4, %esp /* Move esp in state corresponding to eip */
movl %esp, CTX_X86_ESP(%ecx) /* Save esp */
pushf /* Push flags */
pop CTX_X86_EFLAGS(%ecx) /* ...and save them */
movl 0x04(%esp), %ecx /* Point ecx to next registers */
movl CTX_X86_EBX(%ecx), %ebx /* Restore ebx */
movl CTX_X86_EDI(%ecx), %edi /* Restore edi */
movl CTX_X86_ESP(%ecx), %esi /* Restore esp */
movl CTX_X86_EBP(%ecx), %ebp /* Restore ebp */
movl CTX_X86_ESP(%ecx), %esp /* Restore esp */
push CTX_X86_EFLAGS(%ecx) /* Push saved flags */
popf /* Restore flags */
movl CTX_X86_EIP(%ecx), %eax /* Get eip */
push %eax /* Restore it as return address */
ret
线程状态模型
抢占式调度器和协作调度器的一个明显区别是上下文出现的频率。我们看看线程从创建到结束发生了什么。

- 初始状态(init),负责线程的创建,但是并没有假如执行队列。当初始状态完成后,线程完成创建,但是并没有释放内存
- 执行(run)状态很明显,线程由CPU运行
- 就绪(ready)状态表示线程并没有执行,但是等待CPU赋予其时间片,线程处于调度器的队列中
但是一个线程还有其它的状态。当其等待其它时间时,其可以放弃时间片。例如,它可以进入休眠状态,然后继续从休眠的时刻开始执行。
因此一个线程在某个时刻可以出于任何状态(就绪到运行,休眠等),而在协作调度器中,只用一个标记来标记线程的活动就足够了。
通用的线程状态转移图如下:

在上述图中,出现了一个等待状态。它通知调度器其出于休眠状态,知直到其唤醒前,其不需要处理器时间片。接下来,让我们考虑一下抢占式调度器中的API,深入理解线程的状态。
State Implementation
如果仔细观察状态图,你会发现初始状态和等待状态几乎没有区别。他们的下一个状态都只能是就绪状态,它们告诉调度器它们已经准备好获取时间片了,所以初始状态是多余的。
现在看一下退出状态,它具有自己的特殊性。下面将描述它的退出函数在调度器中具体指明。
线程可以有两种方式退出。第一个是线程完成自己的函数执行,释放自己申请的空间;第二个是线程负责资源释放。在第二种情况下,线程可以观测到其它线程释放它自己的资源,通知它执行结束,将控制权返回调度器。在第一种情况下,线程自己释放资源,然后将控制权返回调度器。当调度器获取控制权以后,线程不会继续执行。在两种情况下的退出状态含义相同-线程在这种状态下不想再获取时间片,它不需要再次进入调度器的队列。它不同于等待状态,所以你不需要再创建一个单独的状态。
所以,我们有三种状态,我们将这些状态分成三个独立的域,我们可以使用一个整型变量存储,但是这个使用这种方式是为了简化。所以线程由如下三个状态:
- 激活状态(active),开始并由处理器执行
- 等待状态(waiting),等待某事件发生,它和init和exit事件相同
- 就绪状态(ready),由调度器控制。线程目前在调度器队列中或者开始在处理器上执行。这个状态相对于图中的就绪状态含义更广。在大多数情况下,激活和就绪,就绪和等待在理论上是正交的,但是有一些中间态破坏了这种正交性。下面会仔细阐述该问题。
Creation
线程执行包括所有必需的初始化(thread_init函数),以及一个可能的线程开始。在初始化时,栈上的空间会被释放,处理器上下文会确定,必要的标记以及其它的基本信息。
当创建一个线程时,我们遍历就绪的线程队列,该队列由调度器在任何时间使用。所以我们必须在所有结构完成初始化之前阻止调度器在线程上的操作。当线程的初始化完成后,线程进入等待状态,它与初始状态相同。在这之后,根据传入的参数,我们要么开始线程的运行,要么不开始。线程的开始函数时值调度器里的唤醒函数,后面会详细描述。我们将认为该函数只是将线程放入调度器的队列,然后将线程从等待状态变为就绪状态。线程创建thread_create和初始化thread_init函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
struct thread *thread_create(unsigned int flags, void *(*run)(void *), void *arg) {
int ret;
struct thread *t;
//…
/* below we are going work with thread instances and therefore we need to
* lock the scheduler (disable scheduling) to prevent the structure being
* corrupted
*/
sched_lock();
{
/* allocate memory */
if (!(t = thread_alloc())) {
t = err_ptr(ENOMEM);
goto out;
}
/* initialize internal thread structure */
thread_init(t, flags, run, arg);
//…
}
out:
sched_unlock();
return t;
}
void thread_init(struct thread *t, unsigned int flags,
void *(*run)(void *), void *arg) {
sched_priority_t priority;
assert(t);
assert(run);
assert(thread_stack_get(t));
assert(thread_stack_get_size(t));
t->id = id_counter++; /* setup thread ID */
dlist_init(&t->thread_link); /* default unlink value */
t->critical_count = __CRITICAL_COUNT(CRITICAL_SCHED_LOCK);
t->siglock = 0;
t->lock = SPIN_UNLOCKED;
t->ready = false;
t->active = false;
t->waiting = true;
t->state = TS_INIT;
/* set executive function and arguments pointer */
t->run = run;
t->run_arg = arg;
t->joining = NULL;
//...
/* cpu context init */
context_init(&t->context, true); /* setup default value of CPU registers */
context_set_entry(&t->context, thread_trampoline);/*set entry (IP register*/
/* setup stack pointer to the top of allocated memory
* The structure of kernel thread stack follow:
* +++++++++++++++ top
* |
* v
* the thread structure
* xxxxxxx
* the end
* +++++++++++++++ bottom (t->stack - allocated memory for the stack)
*/
context_set_stack(&t->context,
thread_stack_get(t) + thread_stack_get_size(t));
sigstate_init(&t->sigstate);
/* Initializes scheduler strategy data of the thread */
runq_item_init(&t->sched_attr.runq_link);
sched_affinity_init(t);
sched_timing_init(t);
}
Waiting Mode
线程由于某些原因,其可以切换至其它状态,例如,调用了sleep函数,当前线程从运行状态切换至等待状态。在协作调度器中,我们仅用一个标记来标记这种状态,在抢占式调度器中,为了不丢失线程,我们将线程放在另外一个特殊的队列中。例如,当尝试获取已被占用的互斥锁时,在进入休眠前,线程将自己放入等待互斥锁的队列中。之后当线程等待的事件发生时,线程将被唤醒,我们将线程返回至完成的队列中。
Thread Termination
线程处于等待状态。如果线程执行了相应的函数,并且正常退出,它所占用的资源应该被收回。我已经在退出状态是冗余的部分描述过这个过程。所以,我们看看具体怎么实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
void __attribute__((noreturn)) thread_exit(void *ret) {
struct thread *current = thread_self();
struct task *task = task_self();
struct thread *joining;
/* We can not free the main thread */
if (task->main_thread == current) {
/* We are last thread. */
task_exit(ret);
/* NOTREACHED */
}
sched_lock();
current->waiting = true;
current->state |= TS_EXITED;
/* Wake up a joining thread (if any).
* Note that joining and run_ret are both in a union. */
joining = current->joining;
if (joining) {
current->run_ret = ret;
sched_wakeup(joining);
}
if (current->state & TS_DETACHED)
/* No one references this thread anymore. Time to delete it. */
thread_delete(current);
schedule();
/* NOTREACHED */
sched_unlock(); /* just to be honest */
panic("Returning from thread_exit()");
}
Jumping-off Place for Processing Function Call
我们不止一次提到,当线程结束运行时,它应该释放其占有的资源。在线程执行其函数,按惯例,我们很少需要以非正常的方式结束它,所以我宁愿不调用thread_exit函数。此外,我们需要准备初始化上下文,但是也没必要每次都执行。所以线程将执行一个thread_trampoline cover-function。它用来初始化上下文和正确结束线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
static void __attribute__((noreturn)) thread_trampoline(void) {
struct thread *current = thread_self();
void *res;
assert(!critical_allows(CRITICAL_SCHED_LOCK), "0x%x", (uint32_t)__critical_count);
sched_ack_switched();
assert(!critical_inside(CRITICAL_SCHED_LOCK));
/* execute user function handler */
res = current->run(current->run_arg);
thread_exit(res);
/* NOTREACHED */
}
总结:线程结构描述

为了更加清楚滴描述抢占式调度器,我们需要一个复杂的数据结构,它包括:
- 处理器寄存器的信息(上下文)。
- 任务状态的信息,处于就绪等待执行状态或者等待资源的回收。
- 标记符。就像数组有索引一样。但是如果线程需要增加和删除,最好使用队列,这个时候标记就会很重要。
- 开始函数和参数,也许需要返回值。
- 一块内存空间的地址,为任务执行分配,在线程退出时需要回收。
所以数据结构描述如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
struct thread {
unsigned int critical_count;
unsigned int siglock;
spinlock_t lock; /**< Protects wait state and others. */
unsigned int active; /**< Running on a CPU. TODO SMP-only. */
unsigned int ready; /**< Managed by the scheduler. */
unsigned int waiting; /**< Waiting for an event. */
unsigned int state; /**< Thread-specific state. */
struct context context; /**< Architecture-dependent CPU state. */
void *(*run)(void *); /**< Start routine. */
void *run_arg; /**< Argument to pass to start routine. */
union {
void *run_ret; /**< Return value of the routine. */
void *joining; /**< A joining thread (if any). */
} /* unnamed */;
thread_stack_t stack; /**< Handler for work with thread stack */
__thread_id_t id; /**< Unique identifier. */
struct task *task; /**< Task belong to. */
struct dlist_head thread_link; /**< list's link holding task threads. */
struct sigstate sigstate; /**< Pending signal(s). */
struct sched_attr sched_attr; /**< Scheduler-private data. */
thread_local_t local;
thread_cancel_t cleanups;
};
上面结构中有一些在本文中并没有解释(sigstate, local, cleanups)。他们是为了支持POSIX线程,与本文描述的主题不是很相关。
调度器和调度策略
再次提醒一下读者我们现在有线程的结构,包括上下文,我们在上下文之间切换。此外,我们有一个系统计数器记录时间片。换句话说,我们有调度器的运行环境。调度器的任务是在线程之间分配时间片。为了决定下一个激活的线程,调度器有一个它可以操作的队列,其存储了就绪线程。调度器决定下一个时刻该调度线程的准则称为调度策略。调度策略的主要功能是操作包括就绪线程的队列:增加,删除,决定下一个激活线程。调度器的表现依赖于这些函数的执行。因为我们已经定义了独立的概念,我们将将其划分成一个实体,其接口描述如下:
1
2
3
4
5
extern void runq_init(runq_t *queue);
extern void runq_insert(runq_t *queue, struct thread *thread);
extern void runq_remove(runq_t *queue, struct thread *thread);
extern struct thread *runq_extract(runq_t *queue);
extern void runq_item_init(runq_item_t *runq_link);
让我们考虑调度策略的实现细节。
调度策略的例子
我将只考虑最简单的调度策略作为例子,这样我们就把注意力集中在抢占式调度器的独有特点上。在调度策略中,在不考虑优先级时,线程将被依次处理。一个新的线程或者一个刚刚用完时间片的线程将放置在队列末端。线程从顶端开始依次获取处理器资源。队列用双向列表实现。当我们增加一个元素时,我们将其放置在末端,当我们删除时,从顶端删除。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void runq_item_init(runq_item_t *runq_link) {
dlist_head_init(runq_link);
}
void runq_init(runq_t *queue) {
dlist_init(queue);
}
void runq_insert(runq_t *queue, struct thread *thread) {
dlist_add_prev(&thread->sched_attr.runq_link, queue);
}
void runq_remove(runq_t *queue, struct thread *thread) {
dlist_del(&thread->sched_attr.runq_link);
}
struct thread *runq_extract(runq_t *queue) {
struct thread *thread;
thread = dlist_entry(queue->next, struct thread, sched_attr.runq_link);
runq_remove(queue, thread);
return thread;
}
调度器
接下来是最有意思的部分-调度器
调度器初始化
调度器工作的第一个阶段是初始化。我们需要为调度器提供一个合适的环境。我们准备一个放置就绪线程的队列,将空闲线程假如队列,开始计数器。计数器将用于统计线程执行的时间片。
调度器初始化代码:
1
2
3
4
5
6
7
8
9
10
11
int sched_init(struct thread *idle, struct thread *current) {
runq_init(&rq.queue);
rq.lock = SPIN_UNLOCKED;
sched_wakeup(idle);
sched_ticker_init();
return 0;
}
线程的唤醒和执行
从状态机的描述中,我们发现唤醒和开启线程时同样的过程。在调度器初始化时,该函数将被调用;从空闲线程开始执行。那么在唤醒时发生了什么呢?首先,等待的标记被清楚,以为着线程不再处于等待状态。那么线程存在两种可能的状态:休眠或者不休眠。我将在下一部分等待的描述中解释原因。如果线程不休眠,线程仍然处于就绪状态,唤醒完成。不然的话,我们将线程假如调度器队列,溢出等待标记,放入就绪的线程。如果唤醒的线程的优先级比当前的高,那么需要重新安排执行顺序。注意不同的阻塞:所有的操作都在禁止打断的前提下完成。为了掌握线程唤醒的原因,在对称多处理器中,初始化函数将被调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/** Locks: IPL, thread. */
static int __sched_wakeup_ready(struct thread *t) {
int ready;
spin_protected_if (&rq.lock, (ready = t->ready))
t->waiting = false;
return ready;
}
/** Locks: IPL, thread. */
static void __sched_wakeup_waiting(struct thread *t) {
assert(t && t->waiting);
spin_lock(&rq.lock);
__sched_enqueue_set_ready(t);
__sched_wokenup_clear_waiting(t);
spin_unlock(&rq.lock);
}
static inline void __sched_wakeup_smp_inactive(struct thread *t) {
__sched_wakeup_waiting(t);
}
/** Called with IRQs off and thread lock held. */
int __sched_wakeup(struct thread *t) {
int was_waiting = (t->waiting && t->waiting != TW_SMP_WAKING);
if (was_waiting)
if (!__sched_wakeup_ready(t))
__sched_wakeup_smp_inactive(t);
return was_waiting;
}
int sched_wakeup(struct thread *t) {
assert(t);
return SPIN_IPL_PROTECTED_DO(&t->lock, __sched_wakeup(t));
}
等待
切换至等待模式,然后正确唤醒(当等待事件发生)可能是抢占式调度里最困难的工作。仔细考虑如下的描述:
首先,我们需要向调度器解释我们需要等待某个事件的发生。事件当然不是同步,但是需要将其同步。所以我们应该告诉调度器选择哪个事件的发生。我们不知道它什么时候发生。例如,我们告诉调度器我们等待事件,说明它的出现条件还没有被执行。在这个时候,一个硬件中断发生,它抛出了我们等待的事件。但是当我们准备执行检查时,信息已经丢失。我们通过如下方式解决:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#define SCHED_WAIT_TIMEOUT(cond_expr, timeout) \
((cond_expr) ? 0 : ({ \
int __wait_ret = 0; \
clock_t __wait_timeout = timeout == SCHED_TIMEOUT_INFINITE ? \
SCHED_TIMEOUT_INFINITE : ms2jiffies(timeout); \
\
threadsig_lock(); \
do { \
sched_wait_prepare(); \
\
if (cond_expr) \
break; \
\
__wait_ret = sched_wait_timeout(__wait_timeout, \
&__wait_timeout); \
} while (!__wait_ret); \
\
sched_wait_cleanup(); \
\
threadsig_unlock(); \
__wait_ret; \
}))
线程可能处于多个状态叠加后的状态。当其进入休眠后,设置一个额外的等待标记。在唤醒时,该标记被移除;只有当线程到达调度器,离开了激活线程队列,它才会被重新加入。考虑下述图片的场景:

- A: active
- R: Ready
- W: wait
用字母代替了状态。浅绿色表示状态处于wait_prepare,绿色表示wait_prepare后,深绿色表示重新安排。如果事件在重新安排前没有发生,线程会继续进入休眠并且等待被唤醒。

重新组织
调度器的主要工作是重新组织线程队列。首先,重新组织必须当调度器被阻止后才执行。其次,我们需要指明线程是否允许被抢占。我们将逻辑抽出放置到一个独立函数中,由它调用的块包围和调用,表明在此处我们不允许抢占。
这些动作在就绪线程队列中发生。如果激活线程在重新组织的时刻没有休眠(如果它没有切换至等待状态),我们只是将其添加到调度器的队列中。然后我们从调度器中取出优先级最高的线程。线程的这些规则是先是通过调度策略的帮助实现的。
如果激活线程与从队列中取出的线程时一样的,我们不需要重新组织线程,只需要退出,继续线程执行即可。如果需要重新组织,context_switch和sched_switch将被调用。这些函数中执行调度器需要的步骤。
如果线程进入休眠,切换至等待状态,它将不会进入调度队列,其标记会被清除。最后开始信号处理,但是如上面所述,该内容超越本文主题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
static void sched_switch(struct thread *prev, struct thread *next) {
sched_prepare_switch(prev, next);
trace_point(__func__);
/* Preserve initial semantics of prev/next. */
cpudata_var(saved_prev) = prev;
thread_set_current(next);
context_switch(&prev->context, &next->context); /* implies cc barrier */
prev = cpudata_var(saved_prev);
sched_finish_switch(prev);
}
static void __schedule(int preempt) {
struct thread *prev, *next;
ipl_t ipl;
prev = thread_self();
assert(!sched_in_interrupt());
ipl = spin_lock_ipl(&rq.lock);
if (!preempt && prev->waiting)
prev->ready = false;
else
__sched_enqueue(prev);
next = runq_extract(&rq.queue);
spin_unlock(&rq.lock);
if (prev != next)
sched_switch(prev, next);
ipl_restore(ipl);
assert(thread_self() == prev);
if (!prev->siglock) {
thread_signal_handle();
}
}
void schedule(void) {
sched_lock();
__schedule(0);
sched_unlock();
}
检查多线程操作(ommitted)
本文完