How does tensorflow create a kernel?

This is one of the series of describing how tensorflow works. I will do my best to understand and experiment with tensorflow. In this blog I will introduce how an op and its corresponding kernel is registered and created.
Relation between op and kernel
Kernels are implementation of an op. An op can have different kernels such as on different devices, e.g. CPU, GPU.
Register an OP
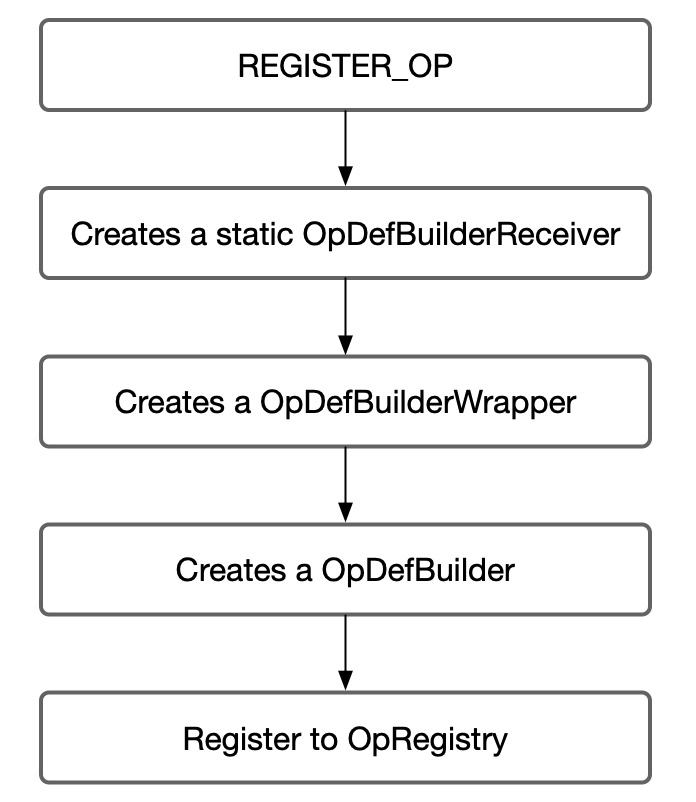
We can register an op by:
1
2
3
4
5
6
7
8
9
// defined in tensorflow/core/framework/op.h
#define REGISTER_OP(name) REGISTER_OP_UNIQ_HELPER(__COUNTER__, name)
#define REGISTER_OP_UNIQ_HELPER(ctr, name) REGISTER_OP_UNIQ(ctr, name)
#define REGISTER_OP_UNIQ(ctr, name) \
static ::tensorflow::register_op::OpDefBuilderReceiver register_op##ctr \
TF_ATTRIBUTE_UNUSED = \
::tensorflow::register_op::OpDefBuilderWrapper<SHOULD_REGISTER_OP( \
name)>(name)
// OpDefBuilder is defined in tensorflow/core/op_def_builder.h
- Here
OpDefBuilderWrapperis a wrap ofOpDefBuilder.OpDefBuildercreates aOpDef. OpDefBuilderReceiverwill call builder'sbuildand add it toOpRegistry
1
2
3
4
5
6
7
8
9
namespace register_op {
OpDefBuilderReceiver::OpDefBuilderReceiver(
const OpDefBuilderWrapper<true>& wrapper) {
OpRegistry::Global()->Register(
[wrapper](OpRegistrationData* op_reg_data) -> Status {
return wrapper.builder().Finalize(op_reg_data);
});
}
} // namespace register_op
__COUNTER__:
COUNTER evaluates to an integer literal whose value is increased by one every time it is found in a source code text.
Register a kernel
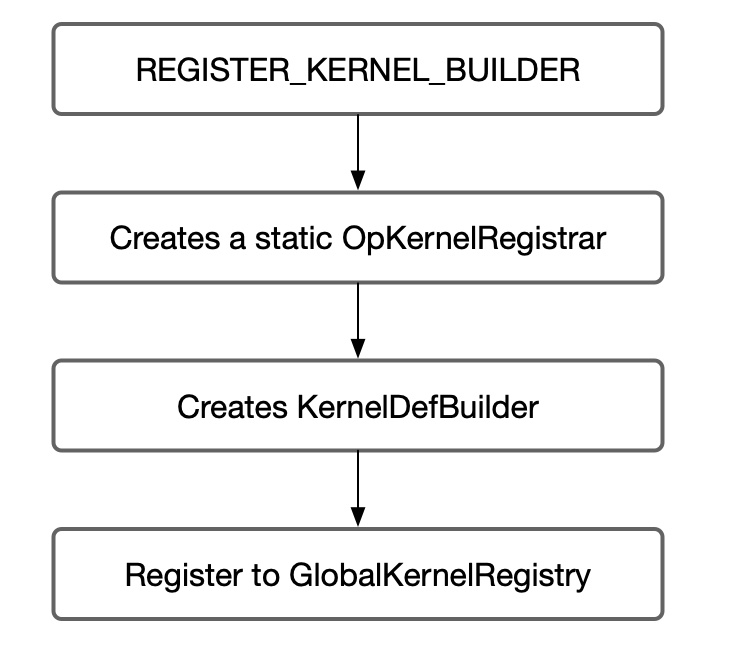
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// defined in tensorflow/core/framework/op_kernel.h
#define REGISTER_KERNEL_BUILDER(kernel_builder, ...) \
REGISTER_KERNEL_BUILDER_UNIQ_HELPER(__COUNTER__, kernel_builder, __VA_ARGS__)
#define REGISTER_KERNEL_BUILDER_UNIQ_HELPER(ctr, kernel_builder, ...) \
REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, __VA_ARGS__)
#define REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, ...) \
constexpr bool should_register_##ctr##__flag = \
SHOULD_REGISTER_OP_KERNEL(#__VA_ARGS__); \
static ::tensorflow::kernel_factory::OpKernelRegistrar \
registrar__body__##ctr##__object( \
should_register_##ctr##__flag \
? ::tensorflow::register_kernel::kernel_builder.Build() \
: nullptr, \
#__VA_ARGS__, \
[](::tensorflow::OpKernelConstruction* context) \
-> ::tensorflow::OpKernel* { \
return new __VA_ARGS__(context); \
});
kernel_builder is defined by
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Name : public KernelDefBuilder {
public:
// With selective registration, kernels whose implementation class is not used
// by any kernel are disabled with the SHOULD_REGISTER_OP_KERNEL call in
// REGISTER_KERNEL_BUILDER_UNIQ. However, an unused kernel that shares an
// implementation class with a used kernel would get through that mechanism.
//
// This mechanism stops that registration by changing the name of the kernel
// for the unused op to one that is ignored by
// OpKernelRegistrar::InitInternal. Note that this method alone is
// not sufficient - the compiler can't evaluate the entire KernelDefBuilder at
// compilation time, so this method doesn't actually reduce code size.
explicit Name(const char* op)
: KernelDefBuilder(SHOULD_REGISTER_OP(op) ? op : "_no_register") {}
};
So we always see this pattern, from Name(op_name)
1
2
3
4
5
6
// defined in tensorflow/contrib/framework/kernels/zero_initializer_op.cc
#define REGISTER_KERNELS(D, T) \
REGISTER_KERNEL_BUILDER( \
Name("ZeroInitializer").Device(DEVICE_##D).TypeConstraint<T>("T"), \
ZeroInitializerOp<D##Device, T>);
);
Tensorflow creates a static OpKernelRegistrar. It uses its constructor to register the kernel factory to GlobalKernelRegistry
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// Registers the given factory function with TensorFlow. This is equivalent
// to registering a factory whose Create function invokes `create_fn`.
OpKernelRegistrar(const KernelDef* kernel_def, StringPiece kernel_class_name,
OpKernel* (*create_fn)(OpKernelConstruction*)) {
// Perform the check in the header to allow compile-time optimization
// to a no-op, allowing the linker to remove the kernel symbols.
if (kernel_def != nullptr) {
struct PtrOpKernelFactory : public OpKernelFactory {
explicit PtrOpKernelFactory(
OpKernel* (*create_func)(OpKernelConstruction*))
: create_func_(create_func) {}
OpKernel* Create(OpKernelConstruction* context) override {
return (*create_func_)(context);
}
OpKernel* (*create_func_)(OpKernelConstruction*);
};
InitInternal(kernel_def, kernel_class_name,
absl::make_unique<PtrOpKernelFactory>(create_fn));
}
}
void OpKernelRegistrar::InitInternal(const KernelDef* kernel_def,
StringPiece kernel_class_name,
std::unique_ptr<OpKernelFactory> factory) {
// See comments in register_kernel::Name in header for info on _no_register.
if (kernel_def->op() != "_no_register") {
const string key =
Key(kernel_def->op(), DeviceType(kernel_def->device_type()),
kernel_def->label());
reinterpret_cast<KernelRegistry*>(GlobalKernelRegistry())
->emplace(key, KernelRegistration(*kernel_def, kernel_class_name,
std::move(factory)));
}
delete kernel_def;
}
So what is GlobalKernelRegistry? It returns a map which stores registration information.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// This maps from 'op_type' + DeviceType to the set of KernelDefs and
// factory functions for instantiating the OpKernel that matches the
// KernelDef.
typedef std::unordered_multimap<string, KernelRegistration> KernelRegistry;
void* GlobalKernelRegistry() {
static KernelRegistry* global_kernel_registry = new KernelRegistry;
return global_kernel_registry;
}
struct KernelRegistration {
KernelRegistration(const KernelDef& d, StringPiece c,
std::unique_ptr<kernel_factory::OpKernelFactory> f)
: def(d), kernel_class_name(c), factory(std::move(f)) {}
const KernelDef def;
const string kernel_class_name;
std::unique_ptr<kernel_factory::OpKernelFactory> factory;
};
How to load a kernel

Currently I am investigating DirectSession, so I will only describe the calling hierarchy for it.
When we initialize an executor, we will need the information for each op:
1
2
3
4
5
6
7
8
// defined in tensorflow/core/framework/executor.cc
Status s = params_.create_kernel(n->def(), &item->kernel);
if (!s.ok()) {
item->kernel = nullptr;
s = AttachDef(s, *n);
LOG(ERROR) << "Executor failed to create kernel. " << s;
return s;
}
1
2
3
4
5
6
7
8
9
10
// defined in tensorflow/core/framework/executor.cc
Status CreateNonCachedKernel(Device* device, FunctionLibraryRuntime* flib,
const NodeDef& ndef, int graph_def_version,
OpKernel** kernel) {
const auto device_type = DeviceType(device->attributes().device_type());
auto allocator = device->GetAllocator(AllocatorAttributes());
return CreateOpKernel(device_type, device, allocator, flib, ndef,
graph_def_version, kernel);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// defined in tensorflow/core/framework/op_kernel.cc
Status CreateOpKernel(DeviceType device_type, DeviceBase* device,
Allocator* allocator, FunctionLibraryRuntime* flib,
const NodeDef& node_def, int graph_def_version,
OpKernel** kernel)
Status FindKernelRegistration(const DeviceType& device_type,
const NodeDef& node_def,
const KernelRegistration** reg,
bool* was_attr_mismatch)
static KernelRegistry* GlobalKernelRegistryTyped() {
#ifdef AUTOLOAD_DYNAMIC_KERNELS
LoadDynamicKernels();
#endif // AUTOLOAD_DYNAMIC_KERNELS
return reinterpret_cast<KernelRegistry*>(GlobalKernelRegistry());
}
Finally we find kernel implementations where we register them.