Estimator OOM after export model frequently
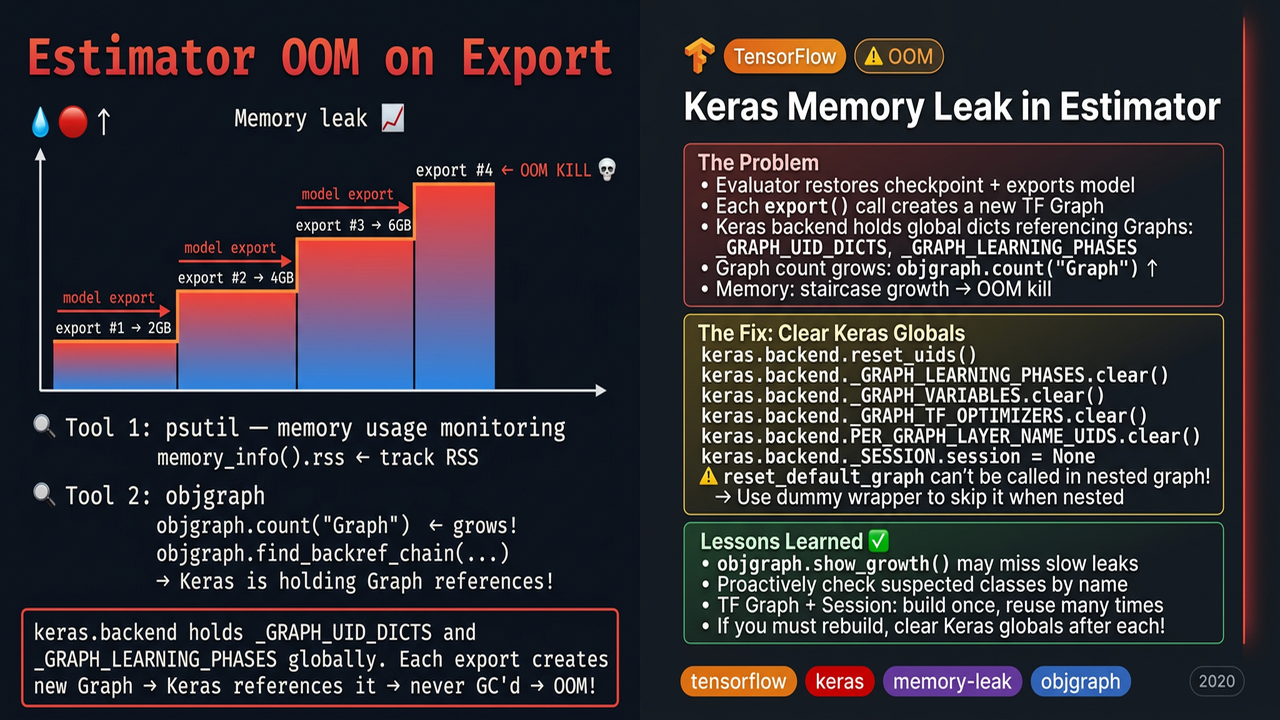
最近用户反馈一个 Estimator 的问题,OOM (out of memory)。由于完全使用的是 Estimator 的逻辑,出错问题 排查了很久。最终使用多个工具找到问题的根源。ps_util 打印内存,objgraph 寻找内存泄露。
背景
我们基于 Estimator 的框架已经稳定运行很久,一直没有异常情况。但是由于内部集群迁移,运行训练任务执行机器从 60GB 规格降低到 15 GB 左右。训练任务运行一段时间后,就会报内存超限被杀。观察内存监控图大致如下:
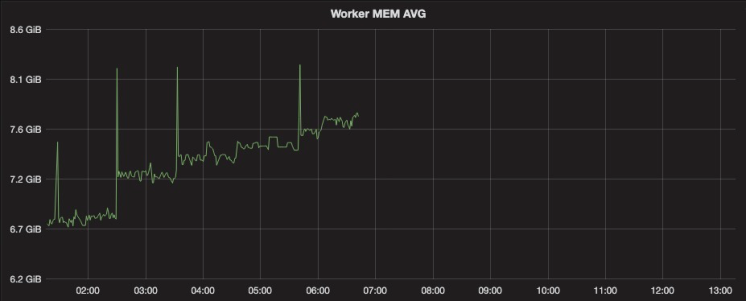
从图中可以发现,内存基本是阶梯式增长(备注:图中的毛刺是因为制造压缩包导致的)。将内存增长点和日志对应,发现两个可疑点:
- 数据 Queue 的 checkpoint
- 类似于 Flink 的 barrier 机制,根据 barrier 会将数据 Queue 中的内存序列化保存,会将序列化的对象保存为内部成员变量。
- 模型导出
- 在线学习系统,每隔一段时间都会触发模型验证,如果验证结果符合预期,会推送给 Serving 端上线。由于模型导出逻辑是 Tensorflow Estimator 的
export_savedmodel接口,出于对 Tensorflow 的信任,前期主要排查数据 Queue 序列化问题。
- 在线学习系统,每隔一段时间都会触发模型验证,如果验证结果符合预期,会推送给 Serving 端上线。由于模型导出逻辑是 Tensorflow Estimator 的
序列化问题
怀疑训练任务消费数据速度过慢,导致数据挤压,Queue 中缓存数据不断增加。在序列化又保存为成员变量时内存超限。通过对比内存平稳期间和内存上涨期间的数据 Queue 的大小,基本稳定。而且 Queue 在存储数据时也有限制:
- 总的数据个数有上限
- Queue 的总内存大小有上限
所以 Queue 中的数据占用应该不会是导致 OOM(Out of memory) 的根因。
模型导出
排除数据缓存导致的 OOM,接下来只剩导出模型的问题。
最小复现样例
MyEstimator定义- train_input_fn
- 制造输入数据
- serving_input_fn
- 导出是创建相应的 placeholder
- memory_usage
- 统计内存使用量
- target
- 封装了函数,便于测试多线程和多进程
1
2
3
python main.py --action train # 训练模型,产出 checkpoint
python main.py --action eval # Restore checkpoint,然后 evaluate
python main.py --action export # 纯粹只导出模型
因为线上是发现导出模型异常,所以单独测试导出模型时的内存变化,发现内存是慢慢上涨,然后到达一个平衡点。似乎线下并没有发现特别异常。但是在线上的确是出现了异常。但是内存仍然是上涨的,推测 Tensorflow 有内存没有被回收。但是现在 Tensorflow 比较复杂,难以快速定位到底是那部分内存没有被回收。
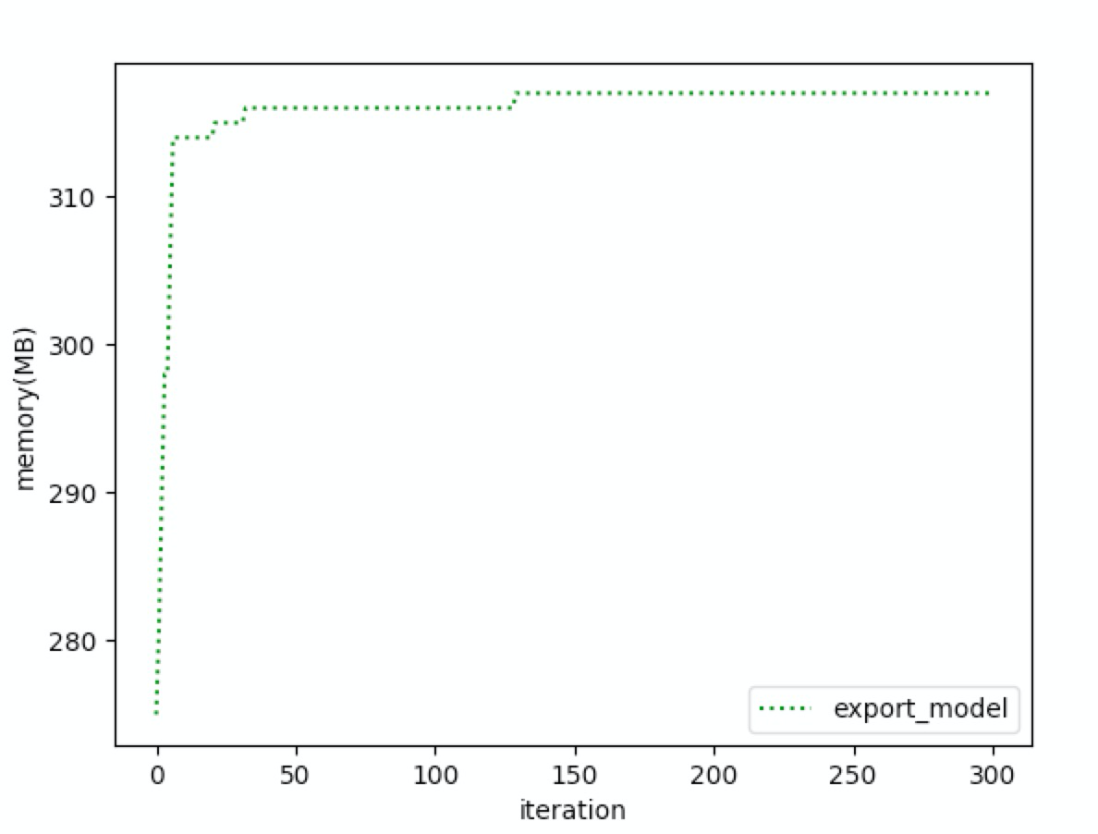
确认内存有上涨,但是找不到原因。为了先解燃眉之急,尝试多线程和多进程的方法。
- 多线程:无效,内存仍然上涨
- 多进程:有效,内存可以稳定
但是在使用多进程时,又遇到另外一个跨进程初始化问题。然后又怀疑是 FileSystem 实现问题。所以局面是:
- 知道内存泄露,但是不知道哪里泄露,通过 objgraph 看头部增长,看不出具体增长类型
- 多进程可以规避,但是多进程在使用上有另外的问题,此外使用多进程给系统稳定性也带来了一定的影响
objgraph 再战
决定使用 Objgraph 再系统性分析下到底哪里出问题。线上使用 Estimator 的方式其实是经典的方式。启动一个 evaluator,当它发现新的 checkpoint 时,会自动 Restore 模型进行打分。如果打分结果符合预期,会调用 estimator.export_saved_model 来导出模型。导出模型时会再次发生 Restore。所以这种情况下会发生两次 Restore,通过在相应位置加入内存统计结果,发现每次 Restore 都会出现内存增长。奇怪的是,线下尝试复现时,复现不了线上类似的结果。基本都是内存开始上涨,然后一段时间后平稳。
测试模型和线上模型现在区别包括两个:
- 线下的模型并没有使用 keras
- 线下的模型并没有使用内部开发的 Embedding Variable 来存储 Embedding
将 MyEstimator 中 x 和 pred 代码做点变动,这样将 keras 引入,暂时不引入内部的 Embedding Variable。
1
2
3
4
from tensorflow.python import keras
x = tf.reshape(x, (-1, 1))
pred = tf.keras.layers.Dense(1, activation="relu")(x)
增加后,发现内存上涨明显。由于是两次 Restore,先将第二次导出模型关闭。不停地去 Restore 模型打分。内存上涨。但是仍然不清楚问题在什么地方。几个主要文件的代码都仔细阅读:
使用 Graph 都用了 with ops.Graph().as_default() , 使用 session 的地方也都使用了相应的 with 语句。正常情况走出作用域,应该随着 python gc 生效都会被清理。
百思不得其解
另外一些业务方并没有遇到这些问题。唯一的区别是他们不会每次都去重建 Session,而是复用现有的 Session 去导出。 于是抱着试一试的心态,通过 objgraph.count("Graph") 看了下 Tensorflow Graph 是否还存在。结果重大发现:个数一直在增长。说明有谁在持有这个引用。利用 objgraph.find_backref_chain 查找到底谁在引用它。 Bingo!是 keras 在引用。在 Github 上发现了 Keras Memory Issue。这里面建议调用相关 clear_session 和 reset_uids 来清理。
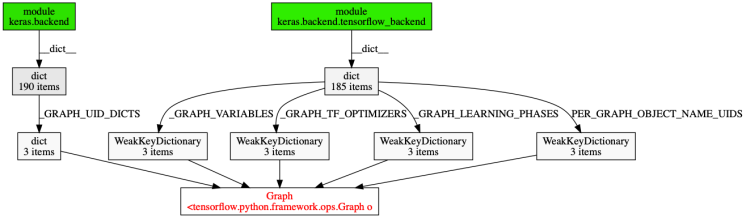
Graph 本身也是循环引用,只能依赖 Python 的 gc 清理它。
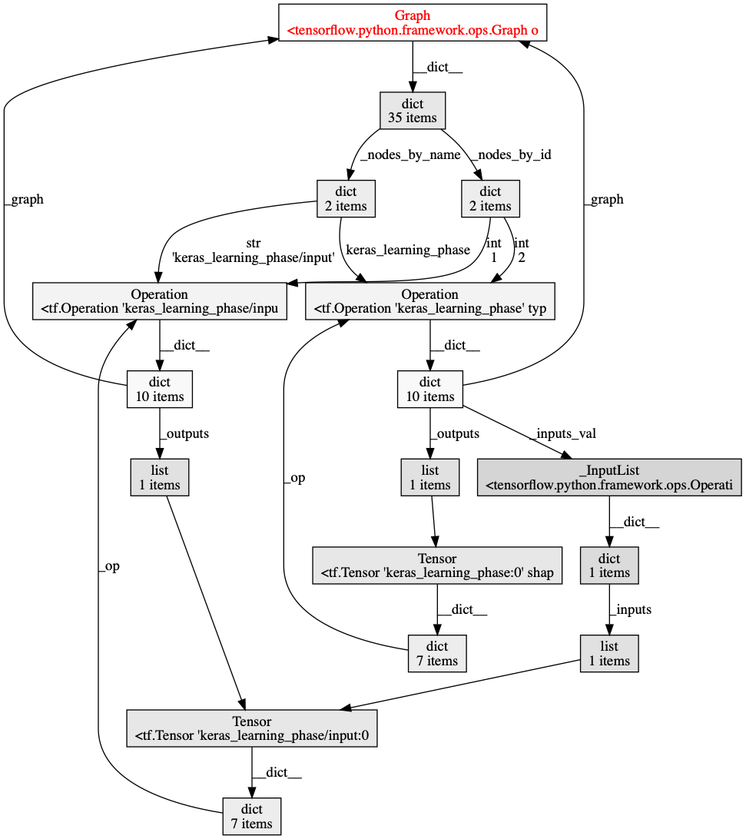
这个图
- Objgraph cnblog
- Objgraph doc
- webgraphviz:可以根据 dot 画图
reset default graph
直接调用 clear_session 或者 reset_uids 代码还不能工作
reset_default_graph不能在嵌套的 Graph 中调用- 在
clear_session函数中,还会去创建新的 Graph
最后代码就是直接调用 keras backend 中相关全局变量的清理。这里用户有混合使用 tensorflow.python.keras 和 keras,导致要清理两个模块中的全局变量:
tensorflow.python.keras.backendkeras.backend.tensorflow_backend
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
import contextlib
import logging
logger = logging.getLogger(__name__)
def clear_keras_related_vars(no_reset=False):
reset_default_graph = ops.reset_default_graph
def dummy_reset_graph():
logger.info("Dummy cleaning")
@contextlib.contextmanager
def wrap_tf_reset_graph(no_reset):
try:
if not no_reset:
ops.reset_default_graph()
except AssertionError:
no_reset = True
logger.info("Not a default graph, skip reset default_graph")
if no_reset:
ops.reset_default_graph = dummy_reset_graph
tf.reset_default_graph = ops.reset_default_graph
yield
ops.reset_default_graph = reset_default_graph
tf.reset_default_graph = reset_default_graph
with wrap_tf_reset_graph(no_reset):
if reset_session:
logger.info("Calling tfplus reset_session")
reset_session()
if backend:
logger.info("Clean native keras.backend.tensorflow_backend")
logger.info(
"Before cleaning _GRAPH_UID_DICTS: %s, _GRAPH_LEARNING_PHASES%s",
len(backend._GRAPH_UID_DICTS),
len(backend._GRAPH_LEARNING_PHASES),
)
backend._GRAPH_LEARNING_PHASES = {}
backend._SESSION = None
backend.reset_uids()
logger.info(
"After cleaning _GRAPH_UID_DICTS: %s, _GRAPH_LEARNING_PHASES%s",
len(backend._GRAPH_UID_DICTS),
len(backend._GRAPH_LEARNING_PHASES),
)
logger.info("Clean tensorlfow.python.keras.backend")
keras.backend.reset_uids()
tf.reset_default_graph()
keras.backend._GRAPH_LEARNING_PHASES.clear()
keras.backend._GRAPH_VARIABLES.clear()
keras.backend._GRAPH_TF_OPTIMIZERS.clear()
keras.backend.PER_GRAPH_LAYER_NAME_UIDS.clear()
keras.backend._SESSION.session = None
lessons learned
- objgraph.show_most_common_types 和 show_growth 有时候会由于泄露的变量增长不是最多,导致被隐藏
- 最好先通过上述函数去直观观察,然后根据经验去判断最有可能泄露的类,主动去统计这些类的个数,观察变化
- reset_default_graph 也不能随便调用,因为可能把 graph 置空,导致已有的一些执行逻辑异常。例如找不到 global_step
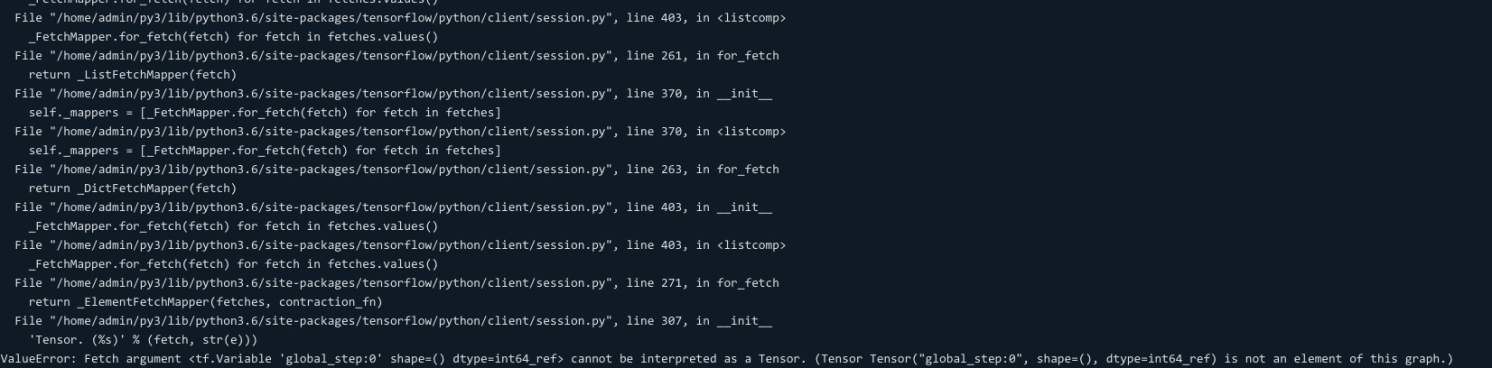
- Tensorflow Graph 和 Session 一般是构建一次,然后重复使用,不断迭代数据。如果需要重复构建 Session 和 Graph 时,需要注意 Graph 是否需要 reset,以及相关引用 Graph 的变量。
参考资料
- tf.Graph https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/Graph
- tf.Session https://www.tensorflow.org/api_docs/python/tf/compat/v1/Session
- Github Issue
- Multiprocess with session: