python pickle
torch.save 和 torch.load 默认使用的 pickle 模块进行序列化和反序列化。在调用 torch.load 时偶尔会遇到缺失类的问题。这篇文章仔细分析了 pickle 的源码,并且对于 缺失类也提供了一些解决方案。
背景
Python 中进行序列化和发序列化一般是使用 pickle 模块。
1
2
3
4
5
6
7
import pickle
a = 3
b = pickle.dumps(a)
c = pickle.loads(b)
if a != c:
print(f"Boom")
还有对应向 File-like object 写出的形式
1
2
3
4
5
6
7
8
9
10
11
import pickle
a = 3
with open("a.bin", "wb") as writer:
pickle.dump(a, writer)
with open("a.bin", "rb") as reader:
c = pickle.load(reader)
if a != c:
print(f"Boom")
dumps和 dump区别时,前者使用输出是 io.BytesIO,而不是一个已经已二进制形式打开的文件。 loads和 load区别也是如此。
struct
在研究 pickle 的行为之前,先研究下 struct 这个库。
Byte order
| Character | Byte order | size | Alignment |
|---|---|---|---|
| @ | native | native | native |
| = | native | standard | none |
| < | little endian | standard | none |
| > | big endian | standard | none |
| ! | network(big endian) | standard | none |
- standard 表示根据对应表示,例如 short 是一个 1字节,native 表示使用
sizeof函数计算的结果 - 如果 Character 不在上述之内,那么默认是
@
类型的表格如下:
| Format | C Type | Python Type | Standard size |
|---|---|---|---|
| x | pad byte | no value | |
| c | char | bytes of length 1 | 1 |
| b | signed char | integer | 1 |
| B | unsigned char | integer | 1 |
| ? | _Bool | bool | 1 |
| h | short | integer | 2 |
| H | unsigned short | integer | 2 |
| i | int | integer | 4 |
| I(upper of i) | unsigned int | integer | 4 |
| l(lower of L) | long | integer | 4 |
| L | unsigned long | integer | 4 |
| q | long long | integer | 8 |
| Q | unsigned long long | integer | 8 |
| n | ssize_t | integer | |
| N | size_t | integer | |
| e | half precision | float | 2 |
| f | float | float | 4 |
| d | double | float | 8 |
| s | char [] | bytes | |
| p | char [] | bytes | |
| P | void * | integer |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from struct import calcsize, pack, unpack, unpack_from
proto = 3
another_proto = 2
# Little endian, unsigned char
value = pack("<B", proto)
value += pack("<B", another_proto)
print(value)
size = calcsize("B")
result = unpack("<BB", value)[0]
if proto != result:
print("Boom")
another_result = unpack_from("<B", value, offset=size)[0]
if another_result != another_proto:
print("Boom another")
pickle.dumps 发生了什么?
pickle 在保存时有一个版本参数 protocol 3,默认是兼容版本 = 3。-1 表示最高版本。 pickle._Pickler.dump
protocol = 3
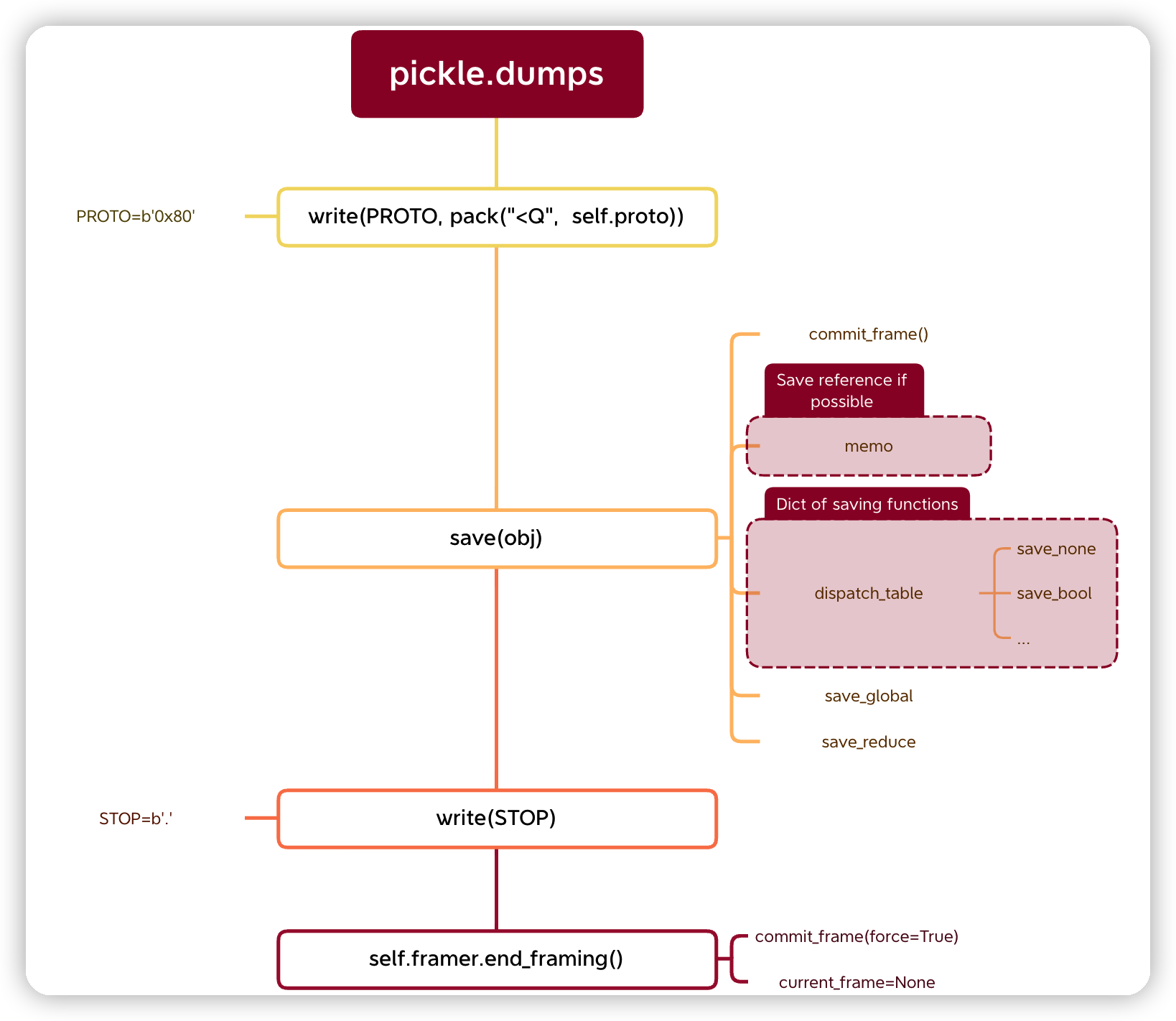
上述的流程图解释如下:
- 输出协议的头
- 输出内容
- 输出停止
end_framing实际上将结果写到 File 对象上。因为不是每次都会去将结果刷出去,特别是对于一些复杂的对象,每次都直接写 File 过于频繁
示例一
1
2
3
4
5
6
7
8
9
import pickle
a = 3
b = pickle.dumps(a)
c = pickle.loads(b)
print(b)
# b'\x80\x03K\x03.'
if a != c:
print("Boom")
- 协议头
- PROTO:
b'x80' - 版本 3 的结果:
\x03
- PROTO:
- a 的类型是
longsave_long去除不必要的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def save_long(self, obj):
# If the int is small enough to fit in a signed 4-byte 2's-comp
# format, we can store it more efficiently than the general
# case.
# First one- and two-byte unsigned ints:
if obj >= 0:
if obj <= 0xff:
self.write(BININT1 + pack("<B", obj))
return
if obj <= 0xffff:
self.write(BININT2 + pack("<H", obj))
return
# Next check for 4-byte signed ints:
if -0x80000000 <= obj <= 0x7fffffff:
self.write(BININT + pack("<i", obj))
return
可以看到 protocol = 3,属于 BININT1,它的值是 K,然后 3 对应的值还是 \x03。最后还有一个 STOP符号,它是 b'.'。
示例二
1
2
3
4
5
6
7
8
9
import pickle
a = [3,898892988]
b = pickle.dumps(a)
c = pickle.loads(b)
print(b)
# b'\x80\x03]q\x00(K\x03J\xbc\x04\x945e.'
if a[1] != b[1]:
print("Boom")
save_list相对于 save_long会有一个 memorize 的调用。这应该是 python 的优化,如果再次遇到同样的变量,就不用再重复保存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def save_list(obj):
self.write(EMPTY_LIST) # ]
self.memoize(obj) # q\x00
while True:
tmp = list(islice(it, self._BATCHSIZE))
n = len(tmp)
if n > 1:
write(MARK) # (
for x in tmp:
save(x) # K\x03 J\xbc\x04\x945
write(APPENDS) # e
elif n:
save(tmp[0])
write(APPEND)
# else tmp is empty, and we're done
if n < self._BATCHSIZE:
return
protocol = 4
save 函数会额外创建 current_frame,其它版本默认是 None。所以并没有先往 current_frame中写出,然后最后写出的优化。start_framing就是创建 current_frame
1
2
def start_frame(self):
self.current_frame = io.BytesIO()
pickle.loads 发生了什么?
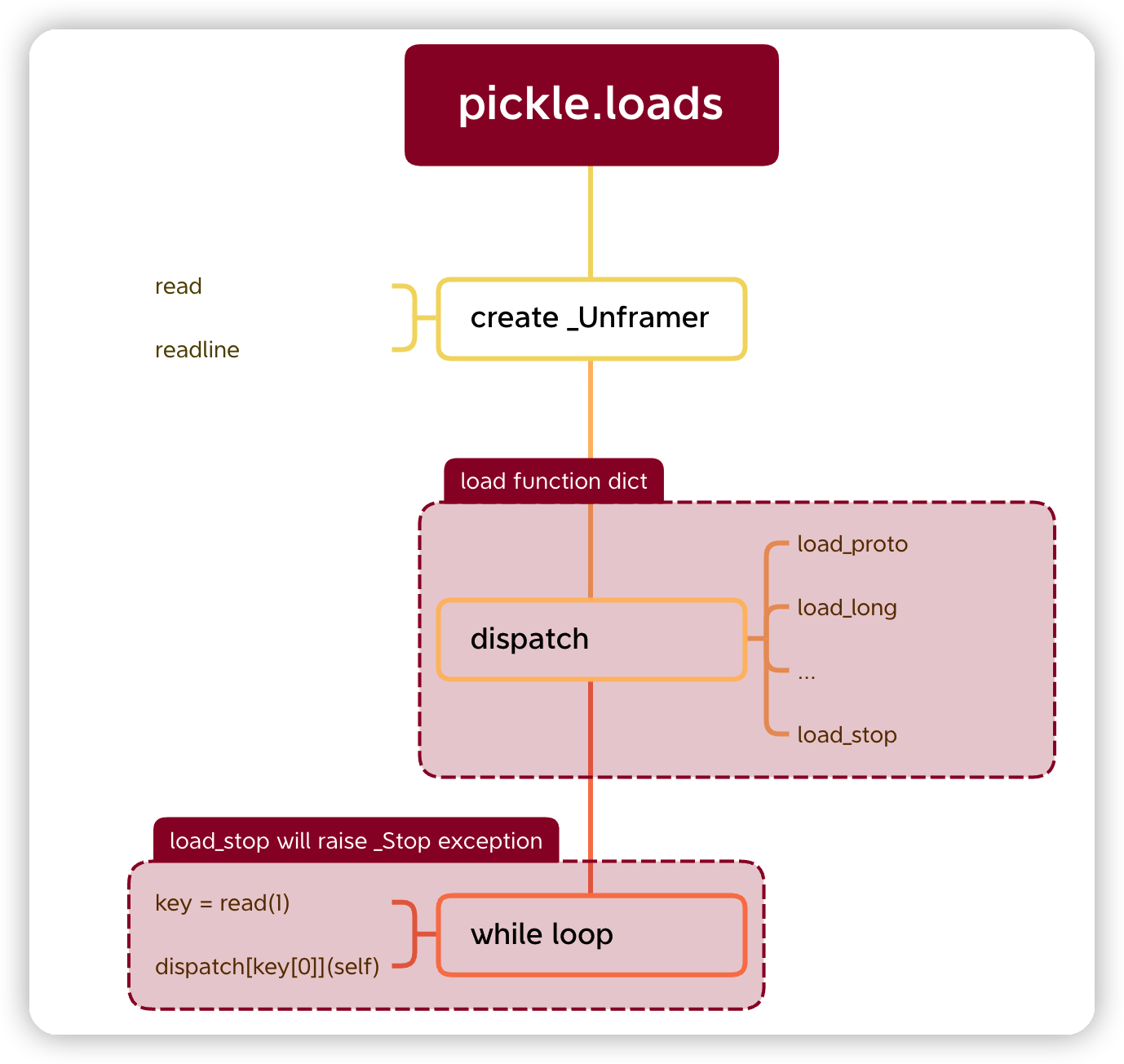
load 和 dump 其实过程基本上是个反向的过程。每一个 load_*函数在末尾都会去调用下述两个操作之一:
- 往
self.stack中增加参数 - 操作 self.stack 进行构建等
1
2
self.append(...) # or
self.stack # related operations
save_global & load_global
当从 dispatch 中找不到对应的类型后,会调用 save_global 或者 save_reduce。目前保存的类型为:
typetype(None)intfloatboolbytesstrtyping.FunctionTypesetdictlisttuplefrozenset
如果找不到如何处理?
copyreg.dispatch_table中查找save_reduce__reduce_ex____reduce__
save_global 会存储 (module_name, klass_name)
whichmodulesys.modules
load_global会将存储的 (module_name, klass_name)找到并且保存起来
find_class
complex case
1
2
3
4
5
6
7
8
9
10
11
12
import pickle
from collections import namedtuple as nt
Person = nt("Person", "name, age")
p1 = Person(name="x", age=3)
res = pickle.dumps(p1)
p2 = pickle.loads(res)
print(p2)
1
b'\x80\x03c__main__\nPerson\nq\x00X\x01\x00\x00\x00xq\x01K\x03\x86q\x02\x81q\x03.'
- PROTO:
x80\x03 - GLOBAL:
c__main__\nPerson\n- memorize:
q\x00
- memorize:
- BINUNICODE:
X\x01\x00\x00\x00x- memorize:
q\x01
- memorize:
- BININT1:
K\x03 - TUPLE2:
x86- memorize:
q\x02
- memorize:
- NEWOBJ:
\x81- memorize:
q\x03
- memorize:
- STOP:
.
AttributeError
pickle 在进行序列化和反序列化时经常出现的一个问题是找不到对应的模块。从上述例子中可以看出, 在保存一些复杂类型时会保存全部的模块路径和类名。如果我们更换了对应的名字,可以导致反序列化失败。 下述代码将一个 Pernson 实例进行序列化并且保存到 pernson.bin 这个文件中。
1
2
3
4
5
6
7
8
9
10
import pickle
from collections import namedtuple as nt
Person = nt("Person", "name, age")
p1 = Person(name="x", age=3)
res = pickle.dumps(p1)
with open("person.bin", "wb") as writer:
writer.write(res)
下述代码尝试反序列化:
1
2
3
import pickle as pickle
with open("person.bin", "rb") as reader:
person = pickle.load(reader)
1
AttributeError: module '__main__' has no attribute 'Person'
解决方案一
保证所有的类在反序列化前可以以原来的方式构建
1
2
3
4
5
6
7
import pickle
from collections import namedtuple as nt
Person = nt("Person", "name, age")
with open("person.bin", "rb") as reader:
person = pickle.load(reader)
解决方案二
在某些情况下,我们的类可能在 A 处定义,但是在 B 处使用。如果我们知道对应的路径,实际上就可以自己去修改。
1
2
from collections import namedtuple as nt
Person = nt("Person", "name age")
1
2
3
4
5
6
7
import sys
from person import Person
import pickle
sys.modules["__main__"].__dict__["Person"] = Person
with open("person.bin", "rb") as reader:
person = pickle.load(reader)
解决方案三
使用 cloudpickle来进行序列化和反序列化
1
import cloudpickle as pickle
解决方案四
方案四和方案三差不多。方案三是本次示例中的比较特殊的情况,我们的模块位于 __main__上。
person.py
1
2
from collections import namedtuple as nt
Person = nt("Person", "name age")
person1.py
1
2
from collections import namedtuple as nt
Person = nt("Person", "name age")
save.py
1
2
3
4
5
6
7
8
9
import pickle
import sys
import person1
sys.modules["person"] = person1
with open("./persin-cp.bin", "rb") as reader:
v = pickle.load(reader)
print(v)
load.py
1
2
3
4
5
6
7
8
9
import pickle
import sys
import person1
sys.modules["person"] = person1
with open("./persin-cp.bin", "rb") as reader:
v = pickle.load(reader)
print(v)
保存时是使用模块 person.Person,但是我们却使用 person1.Person来进行覆盖。这样做有一个风险, 如果对应模块中由其它功能就不能这样直接替换。但是我们可以使用:
1
2
import person1
sys.modules["person"].__dict__["Person"] = person1.Person