sizeof的总结
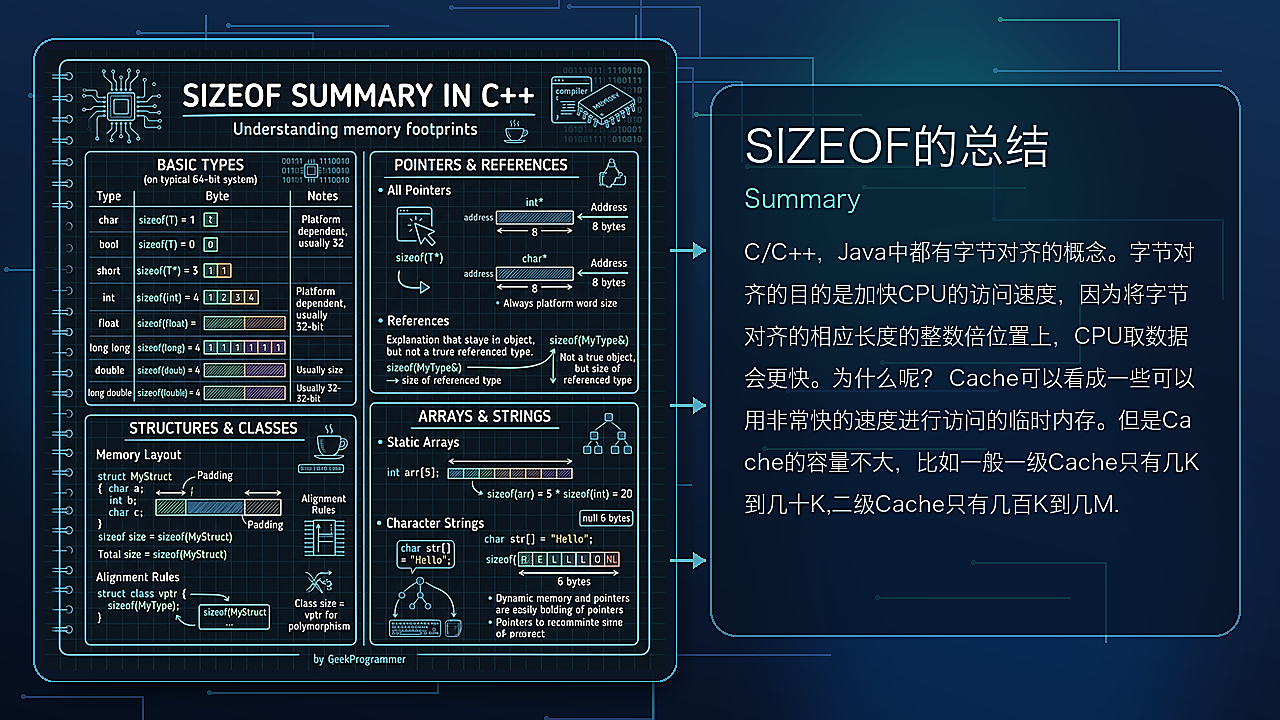
C/C++,Java中都有字节对齐的概念。字节对齐的目的是加快CPU的访问速度,因为将字节对齐的相应长度的整数倍位置上,CPU取数据会更快。为什么呢?
Cache可以看成一些可以用非常快的速度进行访问的临时内存。但是Cache的容量不大,比如一般一级Cache只有几K到几十K,二级Cache只有几百K到几M.这个同数G的内存相比,是比较小的。但是CPU访问内存非常慢,所以硬件会将平时经常使用的内容存放到Cache里面。Cache是通过一些Cache Line来组织的,每一条Cache Line一般包含16个字节,32个字节或64个字节等。 比如某个计算机一级Cache的Cache Line长度是32个字节,那么每段Cache Line总是会包含32个字节对齐的一段内存。现在有一个4字节的整数,如果它的地址不是4字节对齐的,那么就有可能访问它的时候,需要使用两条Cache Line,这增加了总线通讯量,而且增加了对Cache的使用量,而且使用的数据没有在Cache里面(这时需要将数据从内存调入Cache,会非常慢)的机会会增加,这些都降低了程序的速度。参考
C/C++中可以使用sizeof来获取一个结构或者类所占的空间大小,它有三种用法:
- sizeof(obj)
- sizeof obj
- sizeof(Type)
- sizeof Type // error
其中上面第四种形式表示不能直接在类型上不加括号的使用sizeof运算符。sizeof是运算符,它返回其输入的字节数。而且sizeof的值是在编译期间决定的,编译器可以选择进一步优化。
1
2
3
4
5
const char *dog_name = "Lucky";
int dogs[20];
int *dog_ptr = dogs;
const char *dog_name_ptr;
void (*f)(int,int);
分别对上述4个变量做sizeof运算符,在32位机器上,会得到如下结果:6,80,4,4,4。在32位机器上指针都是4个字节长度。但是对于像dogs和dog_name为什么会返回正确的结果呢?因为它们其实也是指针。但是编译器知道我们访问的具体是什么,所以会替我们算出正确的结果。
1
2
auto fun_ptr = [](const char*lhs) { cout<<sizeof(lhs)<<endl;}
auto fun_arr = [](int lhs[]) { cout<<sizeof(lhs)<<endl;}
如果我们将上面的dog_name和dogs分别传入上面的函数(上面我用lambda函数写的,为了方便),打印的结果都是4(32位机器)。这里就会涉及到数组指针的退化问题:函数传递以及[]解引用操作符都会引起退化,退化成一个指针,对这些值取sizeof都会得到相应机器上指针的字节数。
接下来,讨论一下字节对齐的问题。上面介绍过字节对齐的用户,下面直接讨论如何分析一个结构体的所占的大小。
1
2
3
struct MyStruct { int a; int b;};
(int)(&((MyStruct*)0)->a); // 这个代码是计算相对偏移量
offsetof(MyStruct,a); // cstddef头文件中包含这个定义
上面自己写的代码还是利用系统提供的代码都可以计算某个变量在结构体中的偏移量,这样就可以查看编译器会结构体做字节对齐时,补了多少字节。首先给出一个字节对齐的公式:
结构体字节数 = 最后一个变量的偏移量 + 最后一个变量的大小 + 尾部填充字节
结构体中的每个变量的便宜地址都必须是其字节的整数倍:char(1), short(2),int(4),long(4),float(4),double(8),如果没有用宏#pragma pack n,设置对齐要求的话,每个都按自己要求对齐,在设置了以后按照二者的最小值来对齐。每个变量完成字节填充后,都对齐至所要求的位置,然后对整个结构体要求是:结构体的大小必须是结构体内最大对齐数的整数倍。下面举两个例子分别说明。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// example 1
struct Test1
{
char b;
int a;
};
// example 2
struct Test2
{
int a;
char b;
char c;
};
对上述两个结构体分别作sizeof运算会得到:8,8。char对齐要求偏移量是1的整数倍,int要求是4的整数倍。对于Test1,b的偏移量是0,满足;如果不填充字节,那么int是1,不满足,所以在char后填充3个字节,此时int偏移量是4,结构体总字节是8。
在Test2中,a的偏移量是0,满足;b的偏移量是4,c的偏移量是5,总字节是6。但是6不是最宽类型int的4的整数倍,所以末尾还要增加2个字节作为对齐,所以其字节数时8。在Test1中,我们并未分析整个总字节数问题,因为其结果正好符合要求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// example3
struct Inner
{
double a;
int b;
};
struct Test3
{
int a;
double b;
char c;
Inner d;
char e;
};
对Test3去sizeof结果是:48。我特地去取了一非常复杂的表达式,综合了内部结构体,字节填充,尾部填充。Inner字节对齐后的结果是16,其最大的字节对齐是8,其必须在8的位置上(即使我们将int和double的位置交换,Inner在Test3内部的对齐也必须是以8的倍数)。
- int a, 其偏移量为0,但是后面是double,对齐为8的倍数,所以其补3字节:8
- double b:8
- char c;因为其后面是按8的倍数对齐,所以其要补7个字节:8
- Innder d:16
- char e:原本不需要填充,那么Test3的大小为41,不是最大的8的倍数,所以补充7个字节,所以总字节数是48。
sizeof在结构体上的运算结果就只能帮你到这了。接下来看看sizeof在class上的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// example 4
class Test4
{
;
};
class Test5
{
int a;
char c;
};
class Test6
{
char c;
int a;
public:
void f() {cout<<"Hi"<<endl;}
};
class Test7
{
char c;
static char b;
int a;
public:
void f() {cout<<"Hi"<<endl;}
};
上面给出了一连串的类,每个的字节大小其实都很容易算,规则如下:
- 按照struct相同的方式算字节填充
- 非虚函数定义不会占用空间
- 静态成员不会占用空间(全局静态存储区)
- 空的类至少有一个字节,因为为了保证每个变量的地址唯一,否则这个空类前后的地址就重复
答案留给大家自己去运算和跑吧。
下面说一下当存在类的继承和虚函数时sizeof是如何给出结果的。(在测试的时候需要一个比较大的坑,在线编译器的指针大小是8字节,导致以为自己的分析错了)其基本规则如下:
- 如果类里面有虚函数那么其大小至少是sizeof(void*)
- 如果类从其它类派生,需要包括其它类的成员变量大小,如果只有一个基类,基类中有虚函数的话,子类中的虚函数就加入这个虚表,在类中保存这个指针。
- 当从多个基类派生时,当不同基类中有虚函数时,要增加多个指针,指向多个不同的虚表
P.S. 如果sizeof(void*)大小的虚函数也要参与字节对齐过程。4字节int和8字节的虚表指针会导致这个类的大小为16。具体的例子大家参考参考文献。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
// example 5
class Base1
{
int a;
public:
virtual void fun1() {};
};
class Derived: public Base1
{
public:
virtual void fun2(){}
};
class Base2
{
public:
virtual void fun3(){};
};
class Derived1:public Base1, Base2
{
public:
virtual void fun4(){}
};
// 菱形继承
class Base3:public Base1
{
public:
virtual void fun5(){}
};
class Base4:pulbic Base2
{
public:
virtual void fun6(){}
};
class Derived2:public Base3, Base4
{
public:
virtual void fun7(){}
};
// 虚继承
class Base5:public virtual Base1
{
public:
virtual void fun8(){}
};
class Base6:public virtual Base1
{
public:
virtual void fun9(){}
};
class Derived3: public Base5, Base6
{
public:
virtual void fun9(){}
};
上面的测试范例综合包括所有虚函数的场景。在32位机器上,虚函数的指针为4字节。
- Base1: 8字节,int 4字节,虚函数指针4字节 = 8字节
- Derived1: 继承自Base1, 4字节指针,继承成员变量4字节
- Base2:只有虚函数指针,4字节
- Derived2: 两个虚表 4+4,加两个成员4, 16
- Derived3: 三个虚表,加一个成员变量,16
以上的分析不知道是否是正确的,在参考文中分析菱形继承和虚拟继承时并没有考虑基类也具有虚函数的场景。但是通过测试发现如下现象:
- 当采用虚拟继承时,基类(若基类有虚函数)的虚表指针也会在派生类中出现,即派生类会增加一个虚表指针的大小
- 当不采用虚拟继承时,只需要关心派生类的基类的情况,以及基类的成员情况,不用增加一个额外的指针。即上面的Derived3中,如果Base1中没有虚函数,那么这个大小就是12字节。Derived有两个虚表指针,加上一个(由于是虚拟继承,只有一份)整型变量。
参考:
本文完